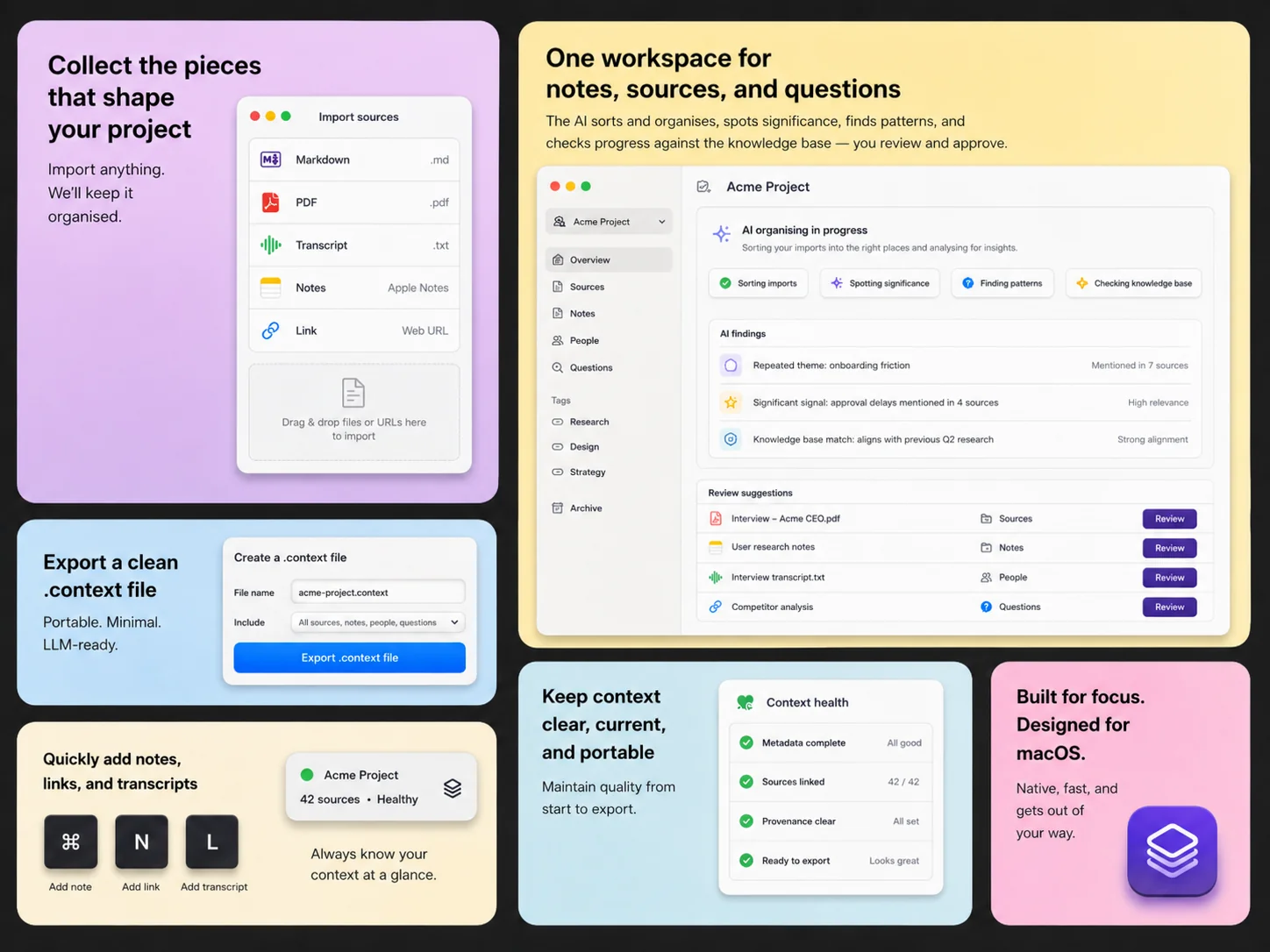
Open Context Format
Pack knowledge.
Make it portable.
.context is an open file format for capturing organisational, project, or domain-specific knowledge in a portable, machine-readable form — ready to load into AI assistants, knowledge tools, or your own applications.